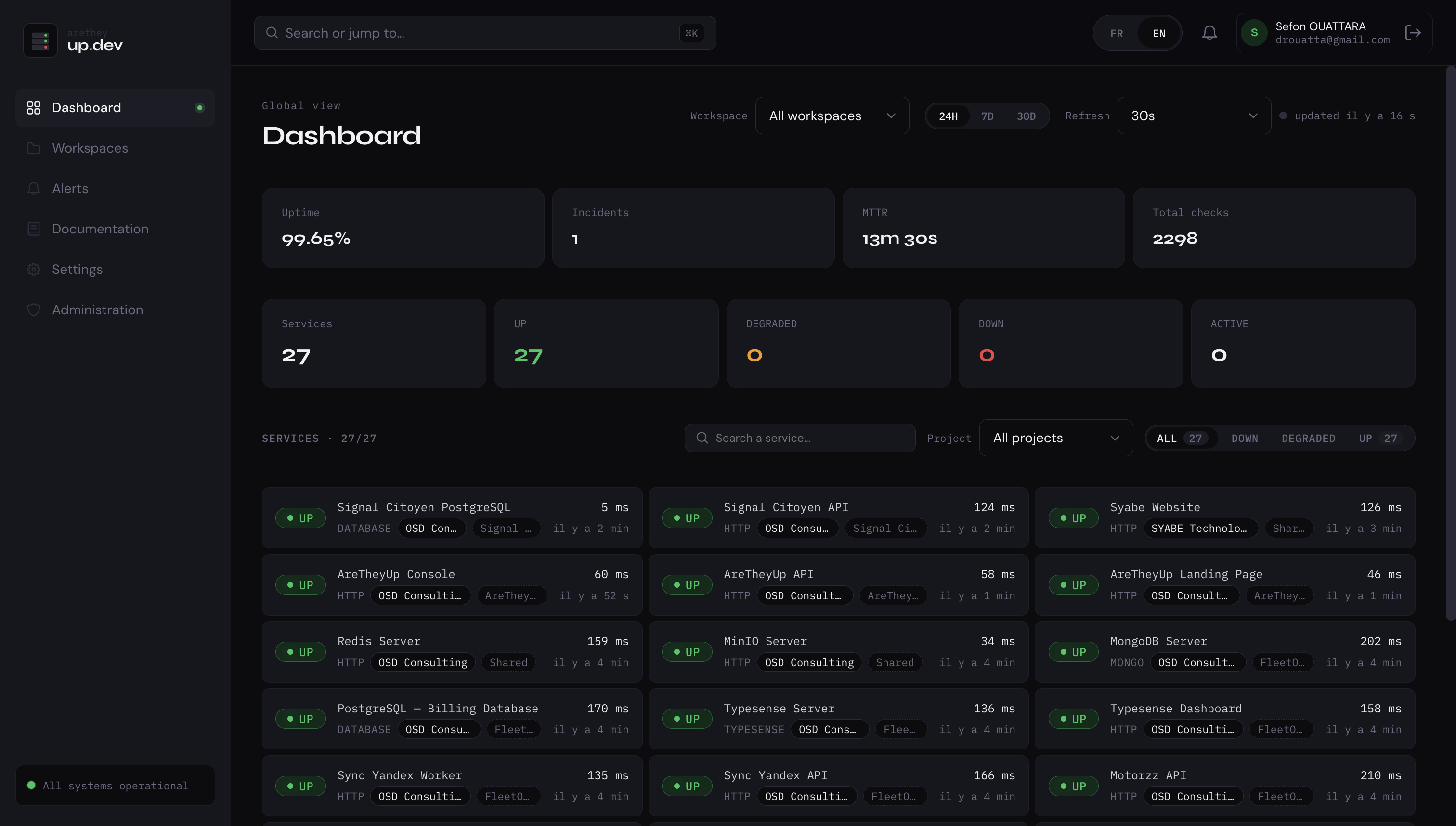
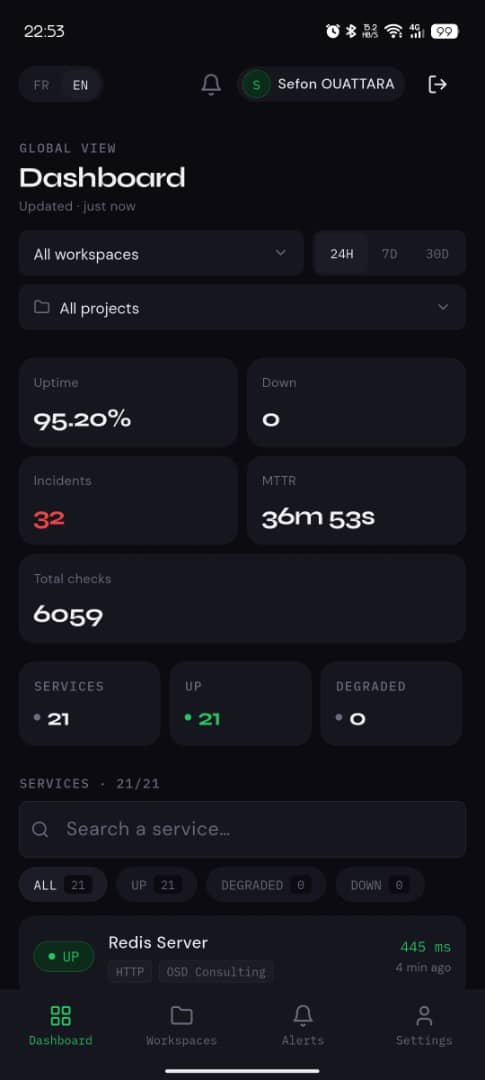
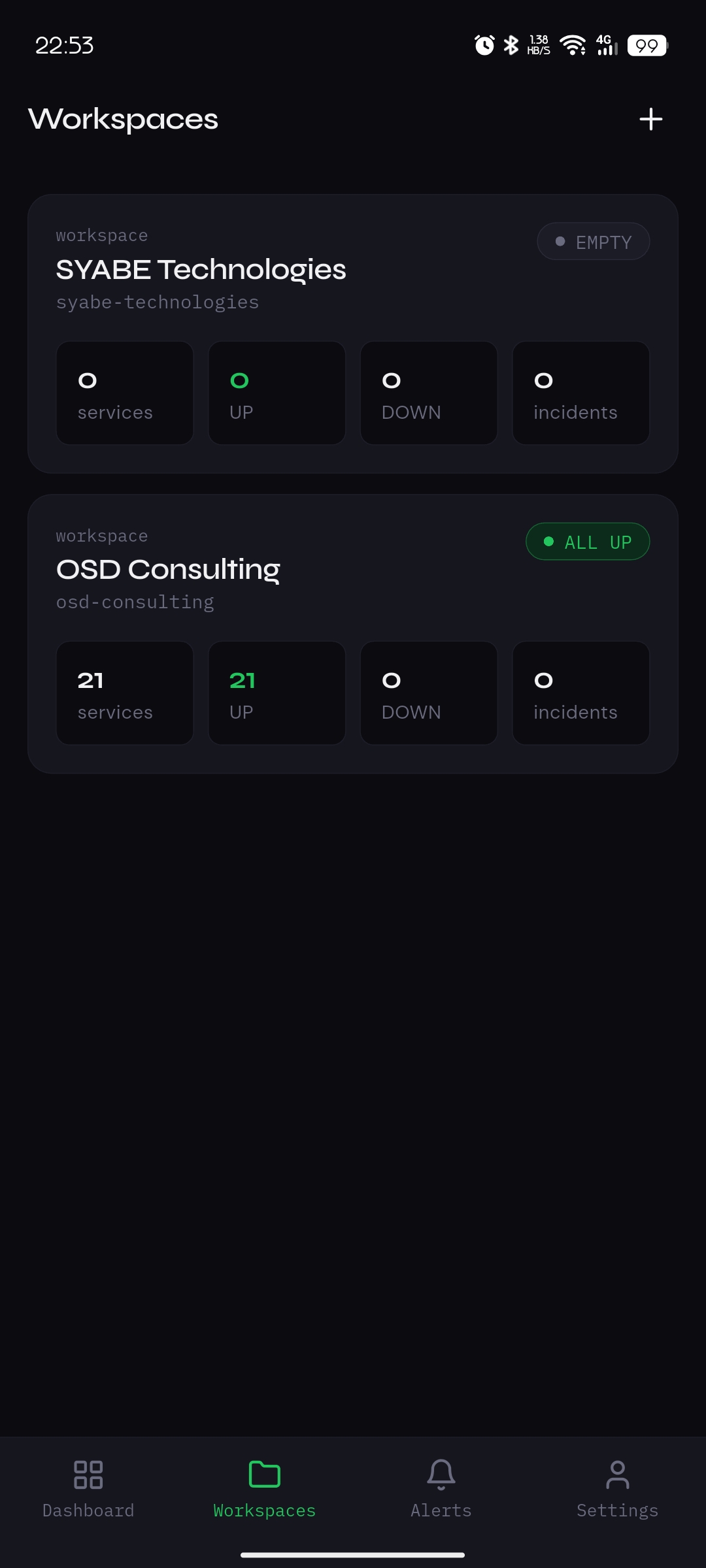
How often should you check your endpoints? It depends on what you'd lose during the gap. A 5-minute interval means you might learn about an outage 5 minutes after it starts — fine for a side project, painful for a checkout flow.
The math: if your worst-case downtime cost is $X per minute, your check interval should be far shorter than the time it takes you to lose $X. For most production apps, 30–60 seconds is the sweet spot. Sub-10-second checking sounds nice but mostly produces alert noise from transient blips.
The exception: anything customer-facing during peak hours — checkout, login, signup — deserves 30s checks even on hobby projects, because the cost of a missed outage is reputational, not just dollar-denominated.